Claude Skill tự cải thiện — vòng lặp Karpathy chạy khi bạn ngủ
Skill chạy 70-80% mà không biết cải thiện sao? Karpathy Loop để AI tự thử, tự chấm, tự giữ thay đổi tốt hơn — hai cách: nhẹ trong Cowork hoặc sâu trong Code.
 Claude Code
Claude Code Claude Cowork
Claude CoworkPlaybook này dành cho ai?
Bạn đã có vài skill (Tạo Claude Skill đầu tiên, Framework 5 phần) — chúng chạy được. Output nhìn khá ổn — khoảng 70-80% trường hợp ưng ý. Bạn debug bằng Debug + maintain skill và đã sửa được những lỗi rõ ràng.
Nhưng 20-30% còn lại thì sao?
Bạn không biết chính xác sai ở đâu. Mỗi lần test, bạn dùng 2-3 input quen thuộc, đọc output, thấy "tạm được" rồi bỏ qua. Vài tuần sau bạn nhận ra "ơ skill này có thể tốt hơn nữa" — nhưng không biết bắt đầu sửa từ đâu.
Đây là tình huống Karpathy Loop sinh ra để giải. Thay vì bạn ngồi đoán → sửa → thử lại — bạn để AI tự thử 50-100 cách sửa, tự chấm điểm theo tiêu chí bạn đặt, tự giữ lại cái nào hiệu quả. Sáng dậy đọc báo cáo. Tên gọi đến từ Andrej Karpathy (đồng sáng lập OpenAI, từng dẫn AI tại Tesla) — người để AI tự sửa code của mình trong 2 ngày, tìm ra 20 thay đổi hiệu quả từ 700 lần thử, cải thiện code anh đã tự tối ưu nhiều năm thêm 11%.
Playbook này dạy bạn pattern đó không cần biết code. Có 2 hướng: Cowork (dùng tính năng eval tích hợp sẵn của skill-creator — 15 phút, 3 prompt, đủ thấy giá trị) hoặc Code (vòng lặp tự động đầy đủ với bảng theo dõi, nâng cao, cho người đã quen Claude Code).
Đây là bài nâng cao, không bắt buộc trong khoá Claude Skills. Đọc Debug + maintain skill (debug bằng tay) trước — bạn phải biết debug thủ công trước khi tự động hoá nó.
Bạn sẽ đạt được gì?
- Đo chất lượng skill bằng bằng chứng thay vì cảm tính ("tôi thấy ổn")
- Rubric 1-5 (chấm thi 6 chiều) → biết skill mạnh/yếu ở đâu cụ thể
- Chuyển chiều yếu thành câu hỏi có/không để AI tự chấm được
- Chạy được 1 vòng lặp đơn giản trên Cowork trong 15 phút (Path A)
- Hiểu blind scoring — vì sao thứ tự "chấm trước, so sánh sau" loại được thiên vị
- Biết áp pattern Karpathy Loop ra ngoài skill — code, prompt cá nhân, content template
Bạn cần chuẩn bị gì?
- Đã đọc Debug + maintain skill — phải biết debug bằng tay 4 triệu chứng trước khi tự động hoá
- 1 skill đang chạy ở mức 60-80% — output khá tốt nhưng bạn biết có thể tốt hơn. Bỏ qua skill < 60% (cần viết lại — xem Tạo Claude Skill đầu tiên) và > 90% (ít dư địa).
- 2-3 input thật để test — bài viết thật, dữ liệu thật, transcript thật. Đừng bịa — input giả thì bảng điểm xuất phát cũng giả theo.
- Mô tả được "output tốt" trông như thế nào — nếu chính bạn không gọi tên được, AI cũng không.
- Tránh skill phụ thuộc API trả kết quả khác nhau mỗi lần (web search live, market data) — khó so trước/sau.
Bức tranh toàn cảnh
Câu chuyện Karpathy
Karpathy có một dự án code anh đã tối ưu thủ công nhiều năm — không ai biết code đó hơn anh. Một ngày anh thử: viết một AI agent đơn giản, giao cho nó task "đổi một thứ nhỏ trong code, chạy test, xem kết quả tốt hay tệ hơn — nếu tốt thì giữ, không thì bỏ và thử cách khác." Đi ngủ. Sáng dậy sau 2 ngày agent chạy không nghỉ:
- Agent đã thử 700 thay đổi
- 680 trong số đó bị bỏ (không tốt hơn)
- 20 thay đổi được giữ — cải thiện hiệu suất code 11%
Phần thú vị không phải con số 11%. Phần thú vị là agent tìm được những thay đổi mà Karpathy chưa từng nghĩ tới trong nhiều năm tối ưu thủ công. Vì agent cứ thế mà thử — không thiên vị, không "tôi biết chỗ này rồi", chỉ đơn giản đo rồi quyết định.
Vì sao debug bằng mắt sẽ bỏ sót
Khi bạn đo bằng mắt, bạn chỉ thấy lỗi rõ ràng. Những thứ "tạm được" thì bỏ qua. Và "tạm được" lặp lại 100 lần vẫn là "tạm được" — không bao giờ thành "tốt thật sự" trừ khi có ai (hoặc thứ gì) đo cụ thể để cho biết khi nào thì khá hơn.
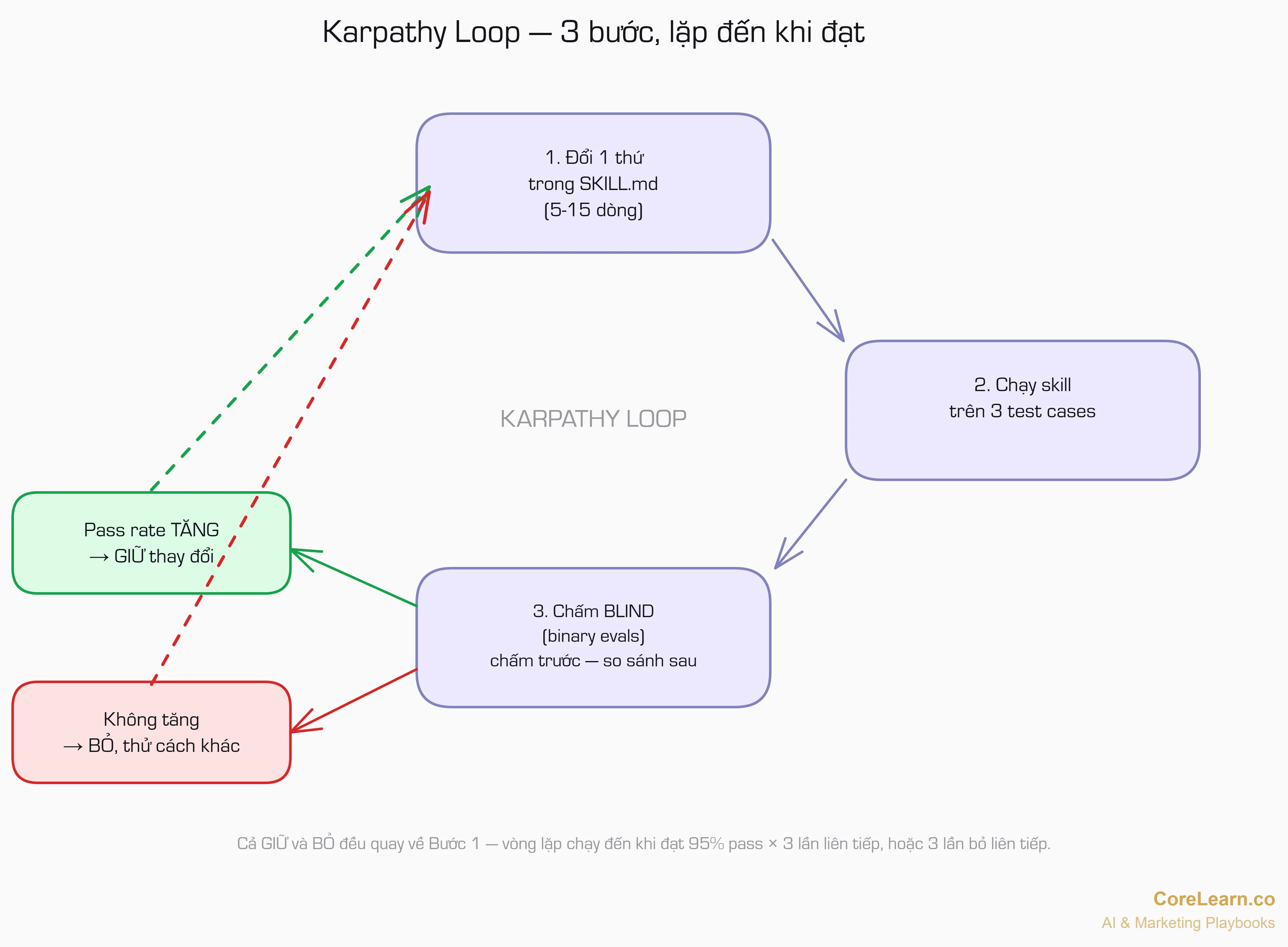
Karpathy Loop làm đúng việc đó: thay vì đo bằng mắt, nó đo bằng câu hỏi có/không cụ thể. Và thay vì bạn ngồi sửa, AI tự đổi rồi tự đo.
3 thành phần cần có
Karpathy Loop chạy được khi bạn có đúng 3 thứ:
| # | Thành phần | Trong context skill là gì |
|---|---|---|
| 1 | Thứ có thể chỉnh | File SKILL.md, reference files, quy tắc |
| 2 | Cách đo kết quả | Câu hỏi có/không cho biết "tốt hơn" hay "tệ hơn" |
| 3 | Cách test nhanh | Chạy skill trên 2-3 input cố định, vài phút có output |
Skill có đủ cả 3. SKILL.md là thứ chỉnh được. Bạn xây tiêu chí đánh giá ở Mục 1-2. Mỗi lần chạy skill chỉ mất 1-3 phút là có kết quả.
Vòng lặp tự chạy. Bạn chỉ duyệt kết quả cuối.
1. Đo bằng "chấm thi 1-5" — không đoán bằng cảm tính
Trước khi để AI tự cải thiện, bạn cần bảng điểm xuất phát (baseline). Đây là con số dùng để so sánh trước/sau — không có baseline, bạn không biết AI có thực sự cải thiện hay không.
Mở khóa toàn bộ nội dung
Bạn đang đọc bản xem trước. Mở khóa để đọc trọn bài này và cả thư viện Pro.
Một lần duy nhất, không gia hạn.
Đã có tài khoản? Đăng nhập
Hoàn tiền 7 ngày · Thanh toán an toàn qua PayOS