Hiểu cách AI tạo ra hình ảnh
Hiểu cách AI biến một câu mô tả thành bức ảnh: từ bộ phiên dịch CLIP, bản đồ tưởng tượng latent space đến kỹ thuật khuếch tán — giải thích đơn giản cho người không chuyên kỹ thuật
 Midjourney
Midjourney Gemini
GeminiPlaybook này dành cho ai?
Bạn đã thử gõ vài câu vào Midjourney, DALL-E hay Gemini và nhận lại bức ảnh đẹp bất ngờ. Nhưng có lúc kết quả sai hoàn toàn — tay người thừa ngón, chữ trong ảnh bị vỡ, hoặc bố cục chẳng liên quan gì đến mô tả. Bạn không biết tại sao lúc đúng lúc sai, nên chỉ còn cách thử đi thử lại.
Playbook này giải thích cách AI tạo ảnh bằng ngôn ngữ đơn giản. Không cần biết lập trình, không cần biết toán. Chỉ cần tò mò muốn hiểu chuyện gì xảy ra phía sau màn hình.
Bạn sẽ đạt được gì?
- Hiểu quy trình AI biến câu chữ thành ảnh qua 2 giai đoạn: bộ phiên dịch CLIP "hiểu ý", kỹ thuật khuếch tán "vẽ ra"
- Biết latent space (bản đồ tưởng tượng) là gì và tại sao mô tả cụ thể cho kết quả tốt hơn
- Hiểu tại sao cùng prompt cho ra ảnh khác mỗi lần — và cách dùng seed để kiểm soát
- 4 kỹ thuật viết prompt tốt hơn dựa trên cách AI thực sự xử lý câu chữ
Bạn cần chuẩn bị gì?
- Không cần cài đặt phần mềm hay biết lập trình
- Tùy chọn: tài khoản Midjourney, DALL-E hoặc Gemini nếu muốn thử thực hành ngay
Bức tranh toàn cảnh
Khi bạn đọc "con gấu ngồi trên thuyền giữa hồ nước", não bạn tự ghép những thứ đã biết — gấu, thuyền, mặt hồ — thành một cảnh mới. Bạn chưa từng thấy cảnh này ngoài đời, nhưng vẫn hình dung được.
AI tạo ảnh hoạt động theo nguyên lý tương tự. Nó học từ hàng tỷ cặp ảnh kèm mô tả bằng chữ, rồi dùng kiến thức đó để tạo ảnh mới từ câu mô tả của bạn. Quy trình gồm hai giai đoạn: giai đoạn đầu AI hiểu câu chữ và tìm ý tưởng phù hợp, giai đoạn sau AI vẽ ảnh bằng cách biến nhiễu thành hình rõ nét.
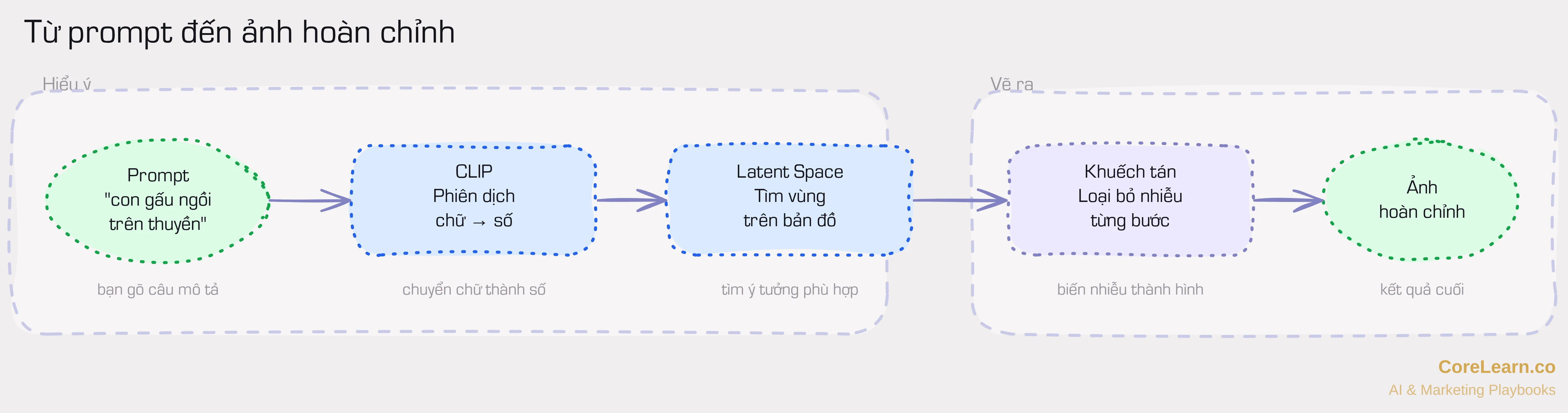
1. Giai đoạn "hiểu ý" — AI đọc câu chữ của bạn như thế nào
Thử một thí nghiệm nhỏ. Đọc câu này rồi nhắm mắt lại:
Một hồ nước yên bình lúc hoàng hôn. Dãy núi ở chân trời. Trên mặt hồ có chiếc thuyền chèo nhỏ. Và ngồi trên thuyền — là một con gấu.
Bạn hình dung được ngay, dù chưa bao giờ thấy cảnh này. Não bạn lấy những mảnh ghép đã có — gấu trông ra sao, thuyền hình gì, hồ nước như thế nào — rồi kết hợp lại thành một bức tranh trong đầu.
AI làm điều giống vậy. Thay vì kinh nghiệm sống, AI học từ dữ liệu — hàng tỷ cặp ảnh kèm mô tả bằng chữ.
Bộ phiên dịch giữa chữ và ảnh
Để hiểu câu chữ của bạn, AI dùng một thành phần tên CLIP (Contrastive Language-Image Pre-training), tức là hệ thống được huấn luyện để so sánh ngôn ngữ với hình ảnh. Hình dung CLIP như người phiên dịch ngồi giữa hai phòng: phòng "chữ" và phòng "ảnh".
Mở khóa toàn bộ nội dung
Bạn đang đọc bản xem trước. Mở khóa để đọc trọn bài này và cả thư viện Pro.
Một lần duy nhất, không gia hạn.
Đã có tài khoản? Đăng nhập
Hoàn tiền 7 ngày · Thanh toán an toàn qua PayOS