Hiểu cách AI tạo ra hình ảnh — từ chữ đến tranh trong vài giây
Hiểu cách AI biến một câu mô tả thành bức ảnh: từ CLIP, latent space đến diffusion — giải thích đơn giản cho người không chuyên kỹ thuật
Playbook này dành cho ai?
Bạn đã dùng Midjourney, DALL-E, hay Gemini để tạo ảnh từ chữ. Gõ vài câu mô tả, AI trả về bức ảnh đẹp — nhưng bạn không hiểu chuyện gì xảy ra bên trong. Tại sao cùng một câu mô tả mà mỗi lần ra ảnh khác nhau? Tại sao có lúc AI hiểu đúng ý, có lúc lại sai hoàn toàn?
Playbook này giải thích cách AI tạo ảnh bằng ngôn ngữ đơn giản. Không cần biết lập trình hay toán học. Chỉ cần tò mò.
Bạn sẽ hiểu được gì sau playbook này?
- Cách AI biến một câu chữ thành bức ảnh — quy trình 2 bước "tưởng tượng" rồi "vẽ"
- "Diffusion" (khuếch tán) nghĩa là gì — và tại sao AI bắt đầu từ nhiễu rồi mới ra ảnh đẹp
- Tại sao cùng một prompt cho ra ảnh khác nhau mỗi lần — không phải lỗi, mà là thiết kế có chủ đích
- Cách viết prompt tốt hơn dựa trên hiểu biết về cách AI xử lý
Bức tranh toàn cảnh
AI tạo ảnh hoạt động giống cách bạn tưởng tượng — chỉ khác là nó dùng toán thay vì não bộ. Khi bạn đọc "con gấu ngồi trên thuyền", não bạn ghép những gì đã biết (gấu, thuyền, hồ nước) thành một hình ảnh mới. AI làm y hệt — nhưng thay vì ký ức, nó dùng hàng tỷ cặp ảnh-chữ đã học.
Quy trình có 2 bước chính: Bước 1 — AI "tưởng tượng" bằng cách hiểu câu chữ của bạn và tìm vùng phù hợp trong "kho ký ức" của nó. Bước 2 — AI "vẽ" bằng cách bắt đầu từ một bức ảnh nhiễu và dần dần chỉnh sửa cho đến khi ra hình rõ nét.
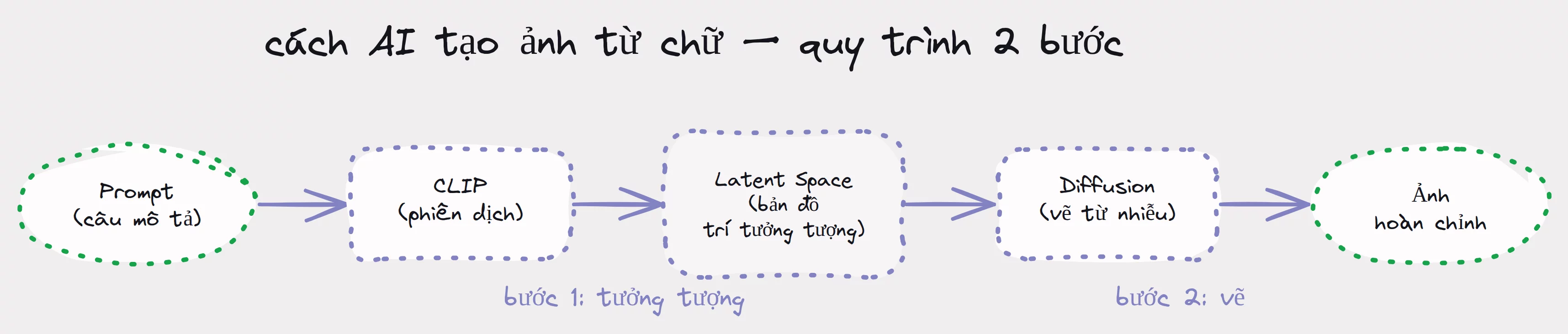
1. AI "tưởng tượng" như thế nào — từ chữ đến ý tưởng
Hãy thử một thí nghiệm nhỏ.
Tưởng tượng một hồ nước yên bình với hoàng hôn tuyệt đẹp và những ngọn núi ở chân trời. Trên mặt hồ có một chiếc thuyền chèo nhỏ. Và ngồi trên thuyền đó... là một con gấu.
Bạn chưa bao giờ thấy cảnh này ngoài đời, nhưng não bạn vẫn ghép được — vì bạn đã biết gấu trông ra sao, thuyền là gì, hồ nước như thế nào. Bạn lấy những mảnh ghép đã có và kết hợp chúng lại.
AI làm điều tương tự. Nhưng thay vì kinh nghiệm sống, AI học từ dữ liệu. Ví dụ, bộ dữ liệu LAION-5B chứa 5,85 tỷ cặp hình ảnh kèm mô tả bằng chữ. AI xem qua tất cả và học được mối liên hệ giữa từ ngữ và hình ảnh.
CLIP — "bộ phiên dịch" giữa chữ và ảnh
Để hiểu câu chữ của bạn, AI dùng một công cụ tên là CLIP (Contrastive Language-Image Pre-training — tạm dịch: hệ thống huấn luyện so sánh ngôn ngữ và hình ảnh). CLIP là "bộ phiên dịch" giúp AI biết từ ngữ nào khớp với hình ảnh nào.